If you're like me, trying to get my sequencing results into a format that is recognisable by Blast, then you've come to the right place! Instead of slowly and tediously deleting every spacing and number in Microsoft Word, I have a nice foolproof shortcut for you to use.
**Edited: Now with screenshots to guide you! :)
1. Paste your sequence (with all the numberings and spaces) into a new word document.

2. Select the search function (Ctrl+F) and choose 'replace'.

3. Next, under 'special' (you can find this at the bottom of the 'replace' interface), choose 'all digits'.

4. Under the replace box, leave it blank (Note! Do not leave even a space there. Backspace that box until the cursor cannot move to the left anymore.)

5. Then click 'replace' and 'yes' to all the subsequent pop ups.

6. Next to remove the spacings, call up the search function again (Ctrl+F).
7. This time put a space in the 'search' box and make sure the 'replace' box is empty.
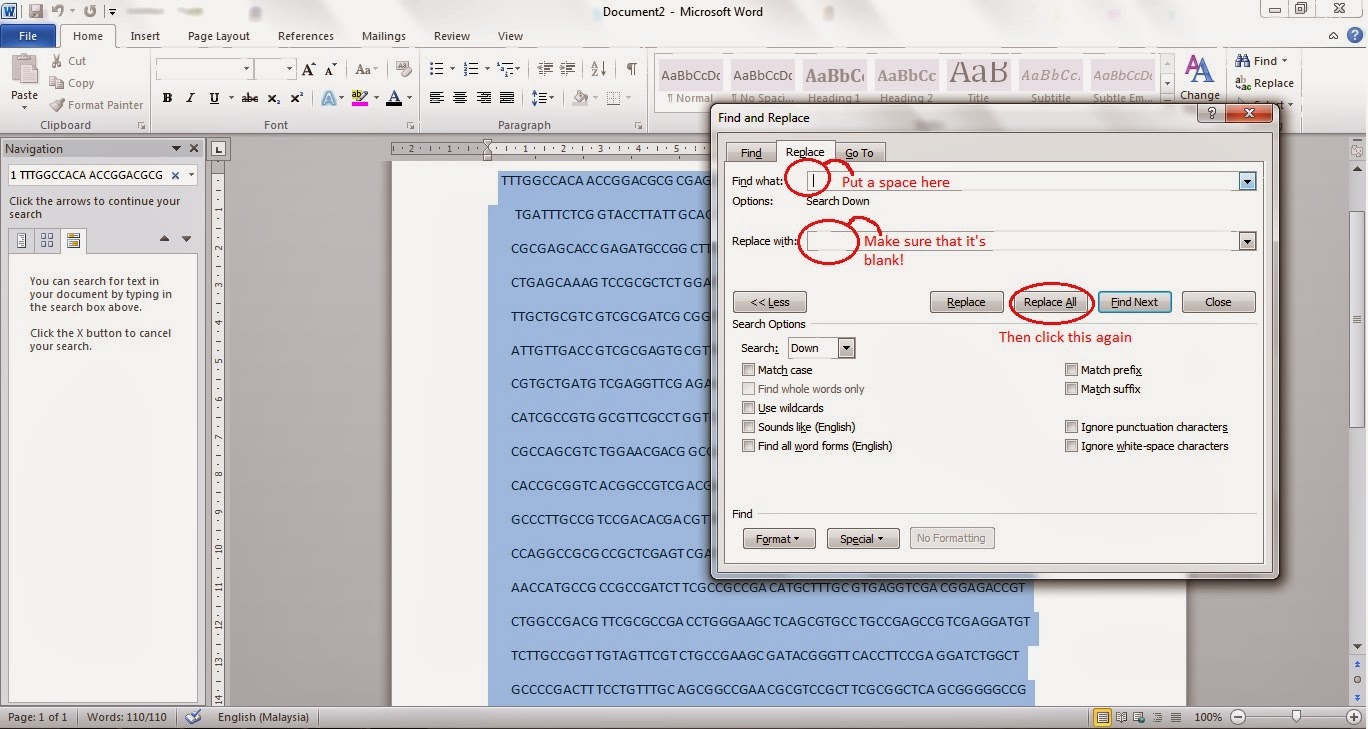
8. Click 'replace' and 'yes' to all the subsequent pop ups.

9. Lastly, connect all the lines of sequence together. You can also set the text to 'full justify' (Ctrl+J) to make the text look nicer.
10. Voila! You have your sequence in FASTA-style format!

OR you can just use this nifty online program: http://genome.nci.nih.gov/tools/reformat.html
Why FASTA?
For easy alignment (using Blast).
Others:
With sequencing results, you'll be also getting chromatographs that can show you whether your sequences are accurate (of good quality) or not. However, you'll also need a software to open the .abi file - I highly recommend this freeware - FinchTV. Link here: http://www.geospiza.com/Products/finchtvdlrequest.shtml
You'll have to fill the form up and you'll get the link to download the software via your email.
Tips for alphabets that are possibly found in your sequence results that are not the usual ATCG:
Tips for keywords that you may see on GenBank/any other seq DB:
(Source: http://seqanswers.com/forums/showthread.php?t=17199)
Feel free to share this handy tip to your fellow lab mates. I've learned this trick at the cost of a meal (have to treat my senior to a meal lol) but I'm sharing it to you FOC :) Have fun!
P/S: This trick works for Mac computers as well, just use the word processing software that your Mac has and use the search function as aforementioned in the instructions and you should be able to get the same results (Tested on Mac by my lab senior lol).
Others:
With sequencing results, you'll be also getting chromatographs that can show you whether your sequences are accurate (of good quality) or not. However, you'll also need a software to open the .abi file - I highly recommend this freeware - FinchTV. Link here: http://www.geospiza.com/Products/finchtvdlrequest.shtml
You'll have to fill the form up and you'll get the link to download the software via your email.
Also, for getting a nice sequence viewer for your sequencing results, I recommend using CLC Sequence Viewer. Link here: http://www.clcbio.com/products/clc-sequence-viewer/ (the download link is right at the bottom of the webpage linked).It's a freeware as well and has this nifty feature where it'll automatically label all the possible restriction sites based on the restriction sites database that they have. It can convert your sequence into various formats as well - with the exception of FASTA-style format unfortunately hehe :P
For converting the sequence that you've obtained from your reverse primer into a complementary sequence, this site, Reverse Complement (Link here: http://www.bioinformatics.org/sms/rev_comp.html), will do the work for you... fast and simple!
If you cannot find your primer sequence in the plasmid/vector sequence, do a reverse complement and try again :) It'll work.
Some more resources:
For converting the sequence that you've obtained from your reverse primer into a complementary sequence, this site, Reverse Complement (Link here: http://www.bioinformatics.org/sms/rev_comp.html), will do the work for you... fast and simple!
If you cannot find your primer sequence in the plasmid/vector sequence, do a reverse complement and try again :) It'll work.
Some more resources:
- To check for common primer sequences: http://www.addgene.org/mol_bio_reference/sequencing_primers/
- To check for restriction sequence/s: https://www.neb.com/tools-and-resources/selection-charts/alphabetized-list-of-recognition-specificities
- To find plasmid sequence: http://dnasu.org/DNASU/SearchOptions.do?tab=1
- To find your target gene (if it was reported before): http://www.ncbi.nlm.nih.gov/ (use the search function)
Tips for alphabets that are possibly found in your sequence results that are not the usual ATCG:
- R = G A (purine)
- Y = T C (pyrimidine)
- K = G T (keto)
- M = A C (amino)
- S = G C (strong bonds)
- W = A T (weak bonds)
- B = G T C (all but A)
- D = G A T (all but C)
- H = A C T (all but G)
- V = G C A (all but T)
- N = A G C T (any)
Tips for keywords that you may see on GenBank/any other seq DB:
- CDS - coding sequence. It is the start from the transcription start site to the end site. The transcriptional unit. UTRs are transcribed but not coded and, therefore, do not belong to the CDS.
- ORF - Open reading frame. ORF is a sequence with no in-frame stop. You typically have several ORFs in any mRNA - can be 3 or even 6 ORFs for a mRNA. A CDS is often the longest ORF, but it not always is.
- cDNA - is the DNA version of mature mRNA (ie, does not include introns, but include the UTR, such as Kozak sequence etc)
(Source: http://seqanswers.com/forums/showthread.php?t=17199)
Feel free to share this handy tip to your fellow lab mates. I've learned this trick at the cost of a meal (have to treat my senior to a meal lol) but I'm sharing it to you FOC :) Have fun!
P/S: This trick works for Mac computers as well, just use the word processing software that your Mac has and use the search function as aforementioned in the instructions and you should be able to get the same results (Tested on Mac by my lab senior lol).
No comments:
Post a Comment